Collecting logs with CloudWatch + Lambda + S3
Introduction
I am implementing a web service with serverless architecture. Since serverless is a pay-as-you-go service, I wanted to measure how much API the users have used. The easiest way is to record it in the DB every time the API is called, but this is inefficient. So, after researching, I decided to scrape the logs accumulated in CloudWatch at regular intervals, process them, and only store the processed information in the DB.
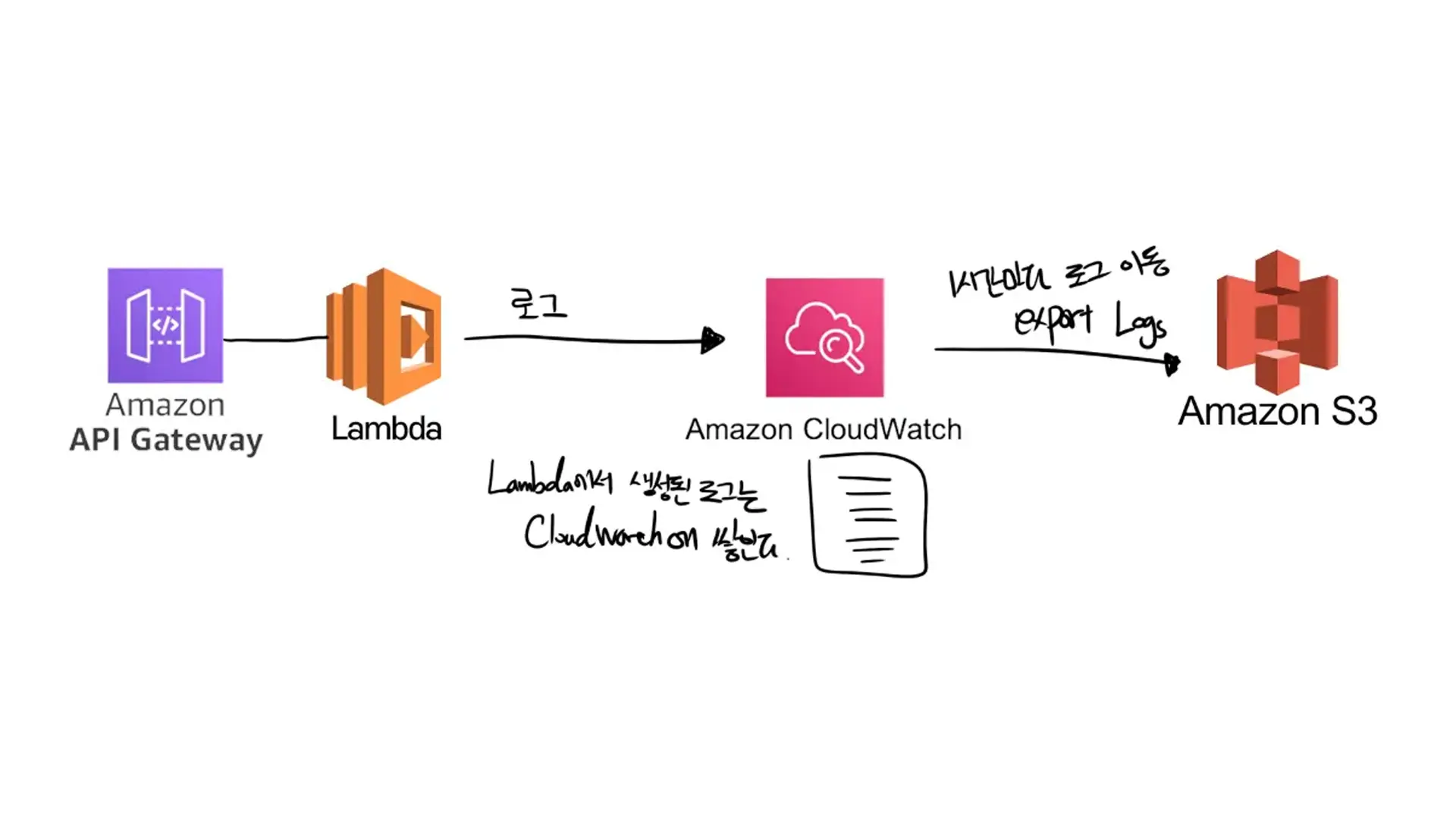
In serverless, APIs are executed through API Gateway + Lambda. And all logs generated during API calls are automatically recorded in CloudWatch without any special measures. I set it to move to S3 every hour. Once the transfer is complete, I read the logs for the past hour from S3, summarize the number of API calls, and store it in the DB.

The reasons for this configuration are as follows:
- The reason for moving CloudWatch logs to S3 is that the storage cost of S3 is cheaper than CloudWatch.
- The reason for calculating and storing user usage every hour is simple. It is because the minimum unit to show user usage on my service dashboard is hourly.
Progress
-
When moving logs stored in CloudWatch to S3, I used CloudWatch.createExportTask supported by aws-sdk. I simply moved it every hour by executing Lambda using a cron schedule expression.

-
Logs were stored in JSON format for easy analysis and management. I used the lambda-log library to store them in JSON format.
After that, it's simple. Analyze the log files as needed, process them into the required format, and you're done.
It may not seem like much, but I spent a lot of time figuring out AWS permissions issues and how Lambda logs are stored in CloudWatch.
